 Denis Barthou
Denis BarthouBackground
Research
Industrial & Community Impact








Software & Tools
I have directly contributed to MAQAO and AFF3CT software, that have now active communities of users, in both industry and academia.
 GitLab
GitLab  Web page
Web page
 GitHub Web page
GitHub Web page
I have also contributed to other software tools through PhD supervision and research projects (e.g., MIPP, PARCOACH), focusing on SIMD abstraction, MPI correctness checking. These projects are actively maintained by their respective communities
I regularly supervise PhD students in collaboration with academic and industrial partners. Please get in touch if you are interested.
This paper presents an optimal and greedy scheduling method for streams on chains of tasks, using both replication (for parallelism) and pipeline, with limited number of cores. It optimizes the throughput of the stream.
PolyTOPS is a configurable, tunable polyhedral scheduler, applied to both compute intensive and AI codes. The configurability allows auto-tuning.
This paper describes how task scheduling methods can impact game engine performance. This was evaluated on Ubisoft game engines.
This is the reference paper for AFF3CT, proposing an efficient framework for the writing of error correcting codes in software defined radios.
The method proposed in this paper is to automatically split and distribute a kernel on multiple GPUs. Provided the kernel is repeatedly executed, a dynamic and efficient load balancing is performed, leading to optimal performance for instance on physic simulation such as n-body simulation.
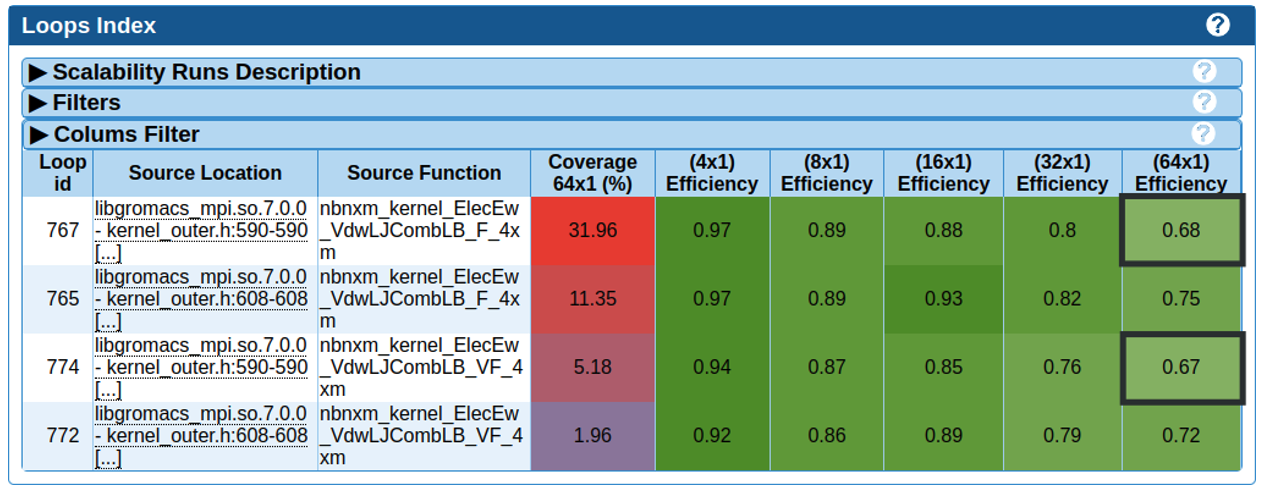
This paper proposes a method based on MAQAO that identifies the access patterns to the data (SoA, AoS, ...) and allows to evaluate the impact of changing this layout on performance. The transformation is directly performed on the assembly code and allows the programmer to quickly have an estimation before an expensive rewrite of the data layout.
Parcoach analyzes statically MPI collectives and adds code to prevent deadlocks whenever the situation may arise, identifying the root cause of the deadlock.
Hydra takes a mathematical equation on matrices and decomposes it recursively in order to create parallel tasks. It enables the automatic production of efficient solvers requiring very little or no cod- ing at all and delivering performance approximating that of the highly tuned library routines such as Intel’s MKL
The journal article is describing how, but analyzing the binary code, MAQAO can help for performance engineering and debugging on multicore architecture.
This paper is on a new method to extend the polydral model to non-affine constraints, in particular for dependence analysis. That is the core of my PhD.